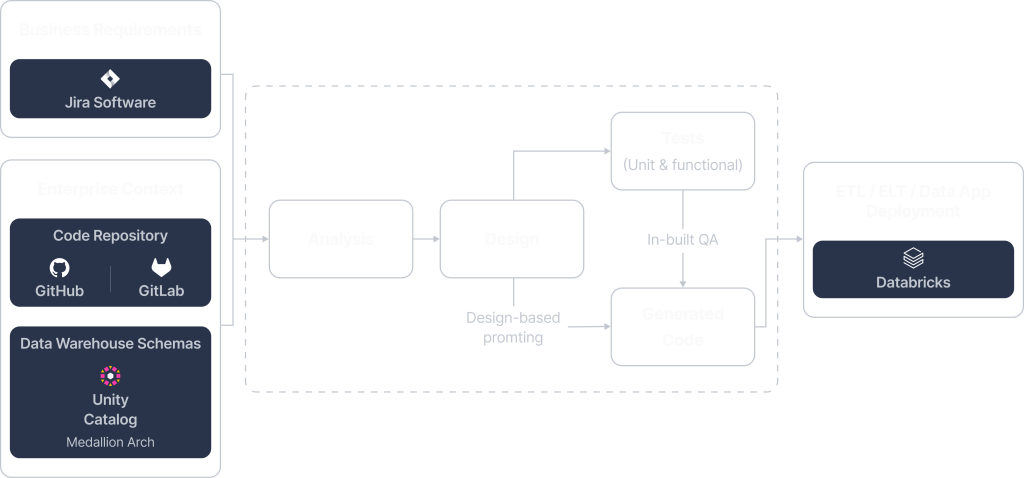
Building and maintaining ETL/ELT pipelines manually is time-consuming, error-prone, and costly. Purgo AI transforms this process by automating each step—from business requirement gathering in Jira to production-ready deployment—ensuring faster implementation, and reduced engineering workload. Below is an overview of how Purgo AI streamlines data pipeline development:
1. Business Requirements Gathering in Jira
At the core of Purgo AI’s automation process is the ability to translate business needs into structured ETL requirements. Instead of relying on ad-hoc handovers, business can define their data processing needs as high-level Jira stories. Purgo AI then analyzes these requirements for completeness, accuracy, and consistency, ensuring that all necessary details are captured upfront. Through iterative feedback loops, the Purgo AI system helps refine user stories, reducing misalignment and accelerating development.
This approach minimizes the need for extensive back-and-forth communication, enabling a streamlined workflow where business and technical teams stay aligned from the start.

2. Enterprise Context Retrieval
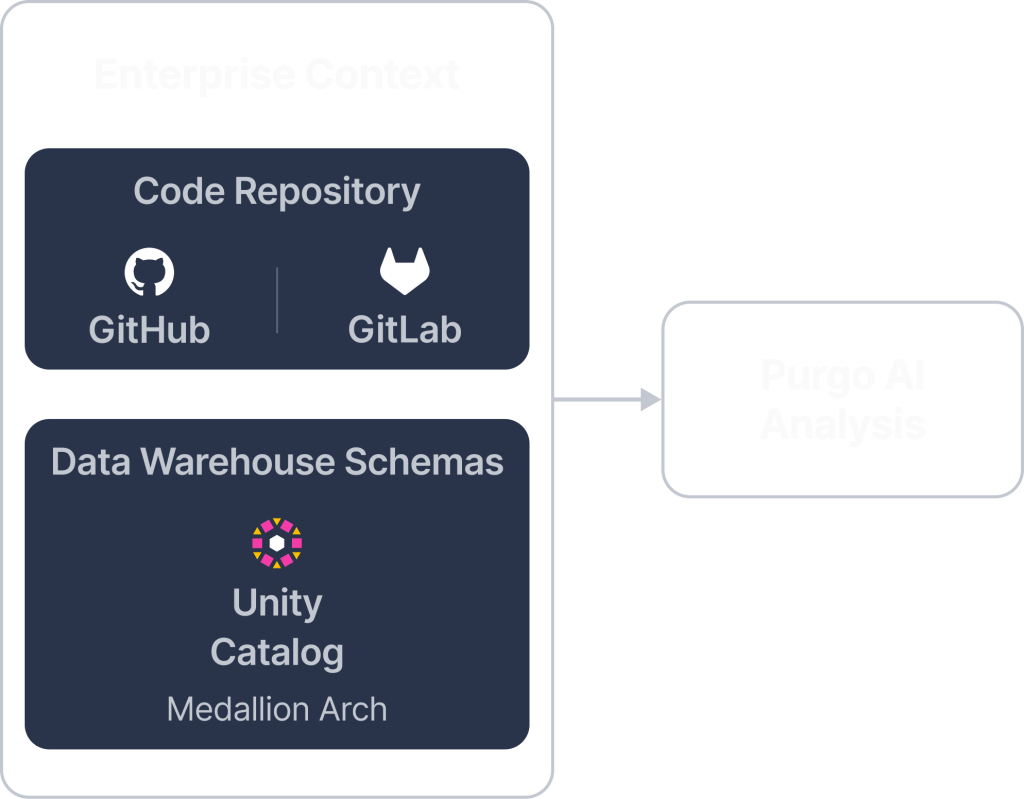
Purgo AI ensures that generated ETL/ELT code aligns with enterprise standards by retrieving relevant data from existing repositories and data warehouse catalogs. This step enhances accuracy and prevents inconsistencies by leveraging contextual insights from:
Intelligent Contextualization: Automates schema and logic retrieval, reducing manual lookup time and ensuring higher code fidelity (80-90% vs. 10-20% for generic AI tools).
Code Repositories: Pulls pipeline logic from GitHub and GitLab, ensuring new transformations align with existing engineering standards.
Data Warehouse Catalogs: Extracts structural metadata from Databricks Unity Catalog, Snowflake Polaris, etc. ensuring queries use correct table structures and column definitions.
3. Design Phase
Purgo AI employs Behavior-Driven Development (BDD) to ensure that ETL/ELT pipeline designs are structured, testable, and aligned with business needs. This phase translates high-level requirements into detailed, structured design specifications using Gherkin pseudo-code, which provides a human-readable yet formalized way of defining expected behaviors in data processing.

4. Automated Test Generation
After the Design phase, Purgo AI embeds automated testing into the ETL/ELT development lifecycle, ensuring pipelines are reliable and production-ready. It generates unit tests, functional tests, and synthetic test data before developing the code to catch issues early and maintain compliance.
Unit & Functional Tests: Created from structured design specifications to ensure correctness.
Synthetic Test Data: Generates realistic datasets for validation without exposing real enterprise data.
Early Bug Detection: Identifies potential issues before deployment, reducing debugging time.
Compliance & Resilience: Ensures pipelines meet enterprise data quality and governance standards.
By integrating testing early, Purgo AI reduces errors, accelerates deployment, and improves data reliability.

5. AI-Powered Code Generation
Purgo AI leverages advanced AI-driven automation to generate high-fidelity, production-ready code with minimal manual intervention. It ensures that the generated pipelines align with enterprise best practices and compliance standards.
High-Fidelity Code: Uses enterprise context retrieval to ensure accuracy and consistency, reducing the need for manual corrections.
Multi-Language Support: Generates optimized SQL, PySpark, Python, or Jupyter Notebooks tailored to specific ETL needs.
Test-Driven Development (TDD): Incorporates automated test validation before deployment, reducing post-production failures.


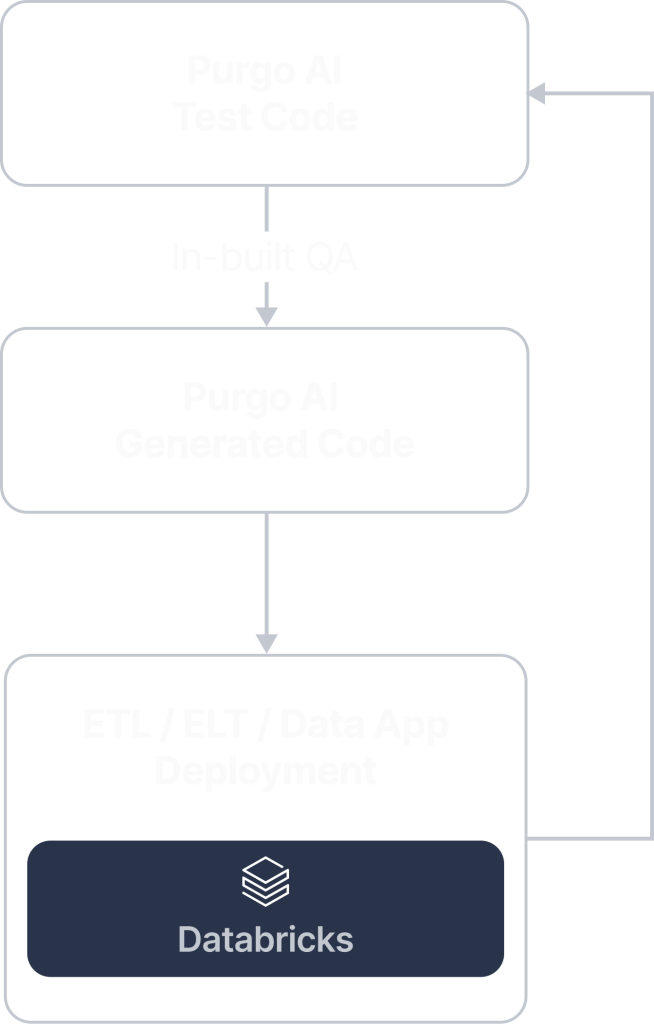
6. Push to Production
Purgo AI seamlessly integrates with modern CI/CD pipelines, automating deployment while ensuring compliance and governance.
After the code passes all tests, Purgo AI agents create a GitHub branch for engineer review and approval, maintaining full traceability. After approval, Purgo AI automates deployment to Databricks, Snowflake, and other cloud data platforms.