In our previous blog, we had described the ongoing paradigm shift in enterprise business applications from being rules-based workflows to becoming data consumption driven. Enterprises are striving to build data consumption efficiency in business operations as a competitive differentiation in the market. Modern cloud data warehouses have taken the centerstage in rearchitecting the traditional and rigid extract-transform-load (ETL) approach to business consumption efficient extract-load-transform (ELT) approach. However, this has created a new need for business-driven data engineering, which cannot be fulfilled manually across multiple points of business consumption.
Alchemy of Racing with Changing Business Requirements
Business-driven data engineering serves as a bridge between the enterprise’s physical world (with customers, vendors, employees, assets etc.) and data world (with catalogs, schemas, ELT compute etc.). The constraints on this bridge limit the ability of the business to consume data for its operations. The demand from business for unprecedented speed, cost-efficiency and domain-awareness in data engineering strain this bridge. In order to mechanize or automate this data engineering, any solution must satisfy the following core functions:
Interpreting Business Intent: The end business outcomes relevant to operations like metrics, comparisons, decisions et al are expressed in business language with words like revenue, cost, inventory etc., which need to be precisely interpreted for delivering data engineering to produce them. This business intent interpretation is a slow collaborative exercise between IT data engineers and business users. The automated system needs to be able to drive these interpretations out of the box.
Reasoning for Solving the Business Requirement: The data engineering system needs to reason with the given business intent and the available data in the catalog to arrive it possible courses of business logic to achieve the outcomes. This involves a process of multi-layer reasoning and validation.
Reliably Implementing the Solution within the Speed-Cost Constraints: The business logic derived in the above step needs to be then implemented over the cloud data warehouse including creation of new business aggregates, source code to drive compute and test cases to validate the implementation.
Traceable, Auditable and Observable by the Shared Data Engineering Team: The automated data engineering system must provide a white-box, explainable, traceable, auditable and observable interface to the shared data engineering team in IT, as they continue to be the custodians accountable for all utilization of the enterprise’s instance of their cloud data warehouse.
These requirements are very challenging to automate as they straddle between data management, distributed systems, code/compiler systems, logic and system reliability. Previous attempts merely yielded incremental productivity tools for the shared data engineering team to use. A true end-to-end business-driven data engineering product had to wait until recent advancements unfolded in generative AI.
Promising Relevant Advancements in Generative AI beyond LLMs
Generative AI offers the most efficient dimensionality and discovery structure yet for knowledge-based computational reasoning. The technology has advanced leaps and bounds beyond its roots in consumer-grade large language models (LLMs) for semantic search and summarization. Here are the most promising advancements in the technology relevant to automated data engineering:
Reasoning over Chains of Associated Thoughts: The most recent advancements in deep reasoning generative AI models (e.g. OpenAI O1/O3, DeepSeek R1) are based on what is being called the Chain of Associated Thoughts (CoAT) framework. This framework can navigate complex multi-layer reasoning necessary for solving advanced problems. The conversion of business intent to data engineering needs this level of sophisticated agentic reasoning for accuracy and reliability. The reasoning layers can also be finetuned with external supervision to boost its accuracy further.
External Context Structures for Constrained Reasoning: The business intent interpretation must be specific to the given enterprise. The chain of associated thoughts needs to be further constrained by an “external brain” created from the enterprise’s data catalog, existing ELT code and past business intents expressed. Advancements in the deep reasoning frameworks allow for encoded direct-acyclic-graph (DAG) driven model control, which can be leveraged to turn the enterprise’s existing data and source code assets into a deep reasoning controller.
Code Generation beyond Textual Prompts: Early use-cases of code generation from LLMs relied on loose natural language-based prompts, which used ambiguous language tokens to generate thousands of formal source code tokens. This method can be an incremental productivity tool at best. Data engineering code generation needs more precise expression than text. Behavior-driven design (BDD) standards like Gherkin offer a much better alternative to text for expressing the technical data engineering design constraints for code generation. Further, these specifications can also be converted to test cases and used for the quality assurance of the code generated.
Reliable Generative AI System Design: Reliability engineering in generative AI has rapidly advanced with technologies like self-reflection, disclosure-based verification, agent-on-agent validation and reinforced learning based on human feedback (RLHF). Data engineering benefits from all these advancements to delivery reliable solutions to business data consumption requirements.
Introducing Purgo AI
Purgo AI combines all the above advancements to deliver LLM based agentic design, development and deployment of data applications over cloud data warehouses. Purgo AI dramatically improves productivity, reduce costs and shortens time to delivery of business-driven data engineering.
Purgo AI is based in Palo Alto, CA and funded by The Hive and Capital One Growth Ventures. The company’s co-founder and CTO, Sang Kim, has been an engineering leader across VMWare and Blackberry. Early users of the product include leading enterprises in the life sciences, media and financial services verticals. Purgo AI’s in-built Vertical Solutions have saved users months of time, cost and efforts by getting to production within days. Prominent execs from several cloud data warehouse leaders are advisors to Purgo AI. The product integrates with leading cloud data warehouses including Databricks, Snowflake, Microsoft Fabric, Google BigQuery and AWS RedShift.
Purgo AI helps automate the building ETL/ELT pipelines and BI applications on cloud data warehouses. The product offers data engineering teams an end-to-end requirements-to-production design, development, test & deployment of ETL/ELT pipelines.
Purgo AI Vertical Solutions come pre-built with comprehensive Process Definition Libraries written by subject matter experts in natural language as easy-to-edit Jira tickets.
Business analysts or product owners specify ETL/ELT user requirements as Jira tickets through Purgo AI’s Jira app either by easily editing in-built process definitions or creating new ones.
This triggers the generation of a design (Behavior-driven design (BDD)) specification. The design creates test harnesses with test scripts and test data for QA.
Purgo AI then generates source code from integrated code-generation LLMs by using the design specifications without needing any human prompting.
For enterprise context the product integrates seamlessly with Github and GitLab (to interpret existing/legacy source code and pipelines), and data warehouse catalogs (for schema).
The generated code is subject to pre-generated quality assurance tests, and test fails re-trigger generation of the source code. The final source code is ready for end deployment over the cloud data warehouse after inspection/approval by the business analyst team.
Product Review of Purgo AI
Ushering a New Era of Data and AI-driven Business Applications
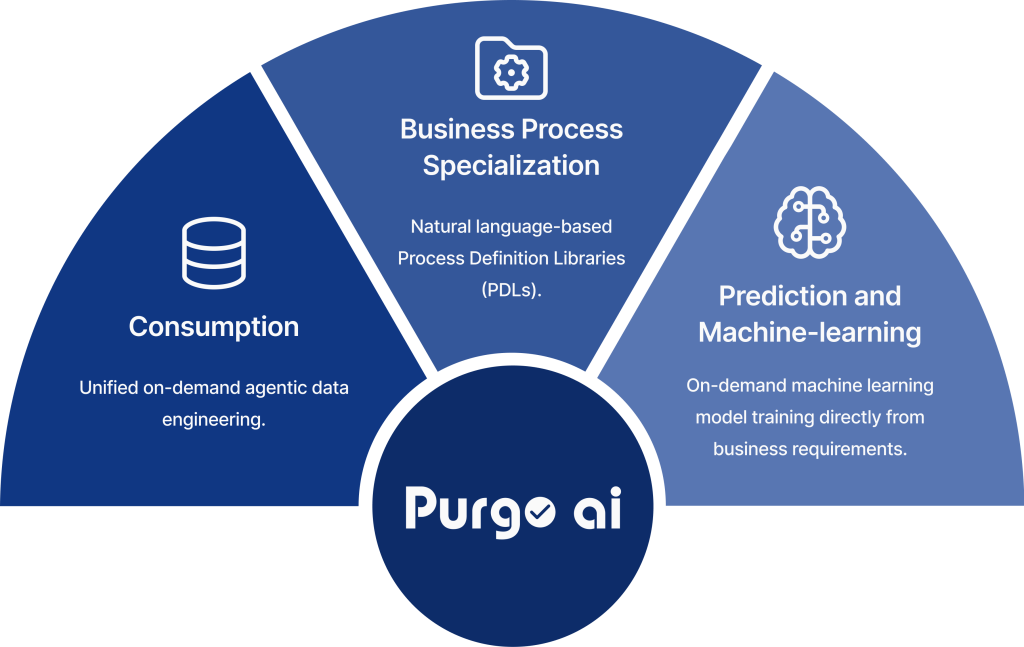
Purgo AI is poised to usher a new era of data and AI-driven applications with its ambitious roadmap and a strong partner ecosystem comprising of both cloud data warehouse leaders and system integrators. The company’s three step product roadmap enables the company to lead the shift in the business application landscape:
Consumption: Purgo AI’s current product consolidates all business-driven consumption of cloud data warehouses into a unified on-demand agentic data engineering with the necessary speed, cost efficiency, domain-awareness and reliability.
Business Process Specialization: Purgo AI is building natural language-based Process Definition Libraries (PDLs) for adding pre-trained domain knowledge for specific industry verticals (like life sciences) and business function (like sales & marketing). This brings sharp business context and intent interpretation capabilities out-of-box in the product. It also allows system integrator partners to build domain specializations over Purgo AI and implement their own versions of PDLs.
Prediction and Machine-learning: Purgo AI plans to release on-demand machine learning model training directly from business requirements for prediction, forecasting, anomaly detection and pattern recognition. This will be generally available later in 2025 and will allow business users to include predictive capabilities in their data consumption-driven operations.